O que é a linguagem R? O be-a-bá para iniciantes
Tópicos desse post
- O que é a linguagem R?
- Como a ciência de dados funciona no R?
- Baixando e instalando o R
- O maravilhoso mundo do R
- Primeiro projetinho no R: Visualizando dados
Se você gosta de desvendar problemas, compreender quais suas principais causas e quais as chances deles se repetirem no futuro, você pode ter um pézinho na ciência de dados - assim como nós. Uma das definições da Ciência de Dados é:
Uma disciplina que permite você transformar uma base de dados em informação, insights e conhecimento.
Com ela você pode analisar dados olhando ao mesmo tempo para o passado, presente e futuro. Você pode entender os motivos de dada situação, perceber a existência de padrões e criar modelos para - literalmente - prever o comportamento dessa situação no futuro. 🚀
Para se tornar um cientista de dados é preciso trilhar um longo caminho - que ainda estamos percorrendo - e que envolve o aprendizado de diversas linguagens e ferramentas que irão ajudar nesse processo, como big data, python, estatística e muito mais. A imagem abaixo de Swami Chandrasekaran pode ajudar a visualizar esse caminho:
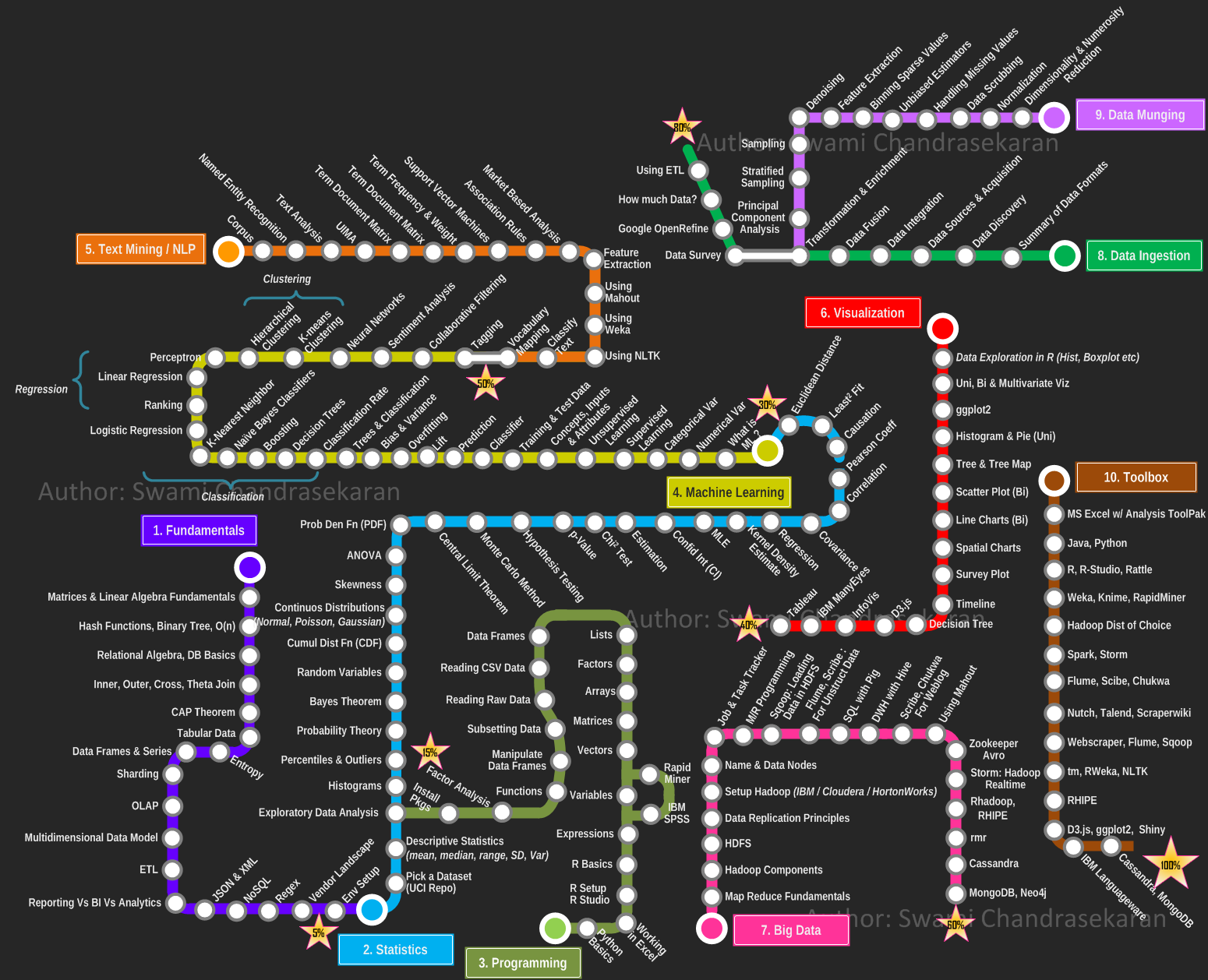
(A gente jura que nosso objetivo não é desanimar mostrando esse monstro.)
Dentre todo esse redemoinho de informações, a gente acredita que o R é a melhor linguagem para começar a aprender a ciência de dados, colocar a mão na massa e já conseguir obter resultados visíveis. Mas o que é a linguagem R?
R é uma ferramenta gratuita e open-source (ou seja, de código aberto) usada para análise de dados estatísticos e visualização da informação, muito utilizada por cientistas de dados e pesquisadores. https://www.r-project.org/
E por que o R é tão legal?
Além do seu aprendizado ser intuitivo e possuir uma comunidade super aberta para troca de conhecimento, o R é uma ferramenta que agrega 3 elementos essenciais em um só programa: manipulação de dados, cálculos e display gráfico. Com ele você consegue fazer muitas coisas, começando por blogs (esse aqui por acaso - ou nem tanto - é feito com R). Alguns outros exemplos:
- Aplicativos web
- Gráficos
- Dashboards
- Artigos acadêmicos
- Blogs (esse aqui é todo feito no R)
- Livros
- Analisar dados de texto quantitativamente
- Machine learning
- Slides
- Minerar dados
- e mais!…
Como a ciência de dados funciona no R?
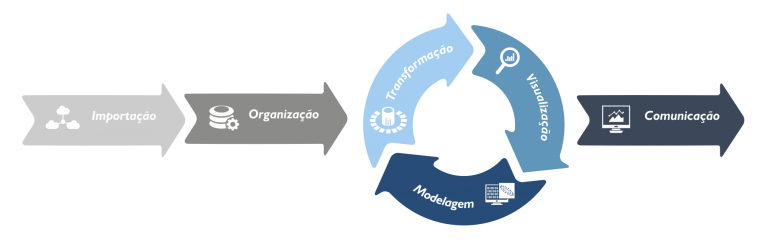
Essa imagem que retiramos da oper representa o fluxo de trabalho que normalmente você realiza ao trabalhar com projetos no R, a ciência de dados funciona no R de acordo com essas características.
- Importação: Importar a base de dados para o R
- Organização: Organizá-la de acordo com suas necessidades
- Transformação: fazer as alterações necessárias de acordo com suas necessidades (adicionar dados, unir tabelas, etc)
- Visualização: transformar a informação em gráficos
- Modelagem: criar modelos preditivos
- Comunicação: juntar tudo o que foi feito, selecionar a informação relevante e transmitir informação
Baixando e instalando o R
Para começar você precisa baixar dois programas:
- R: para Windows e Mac - A raíz do programa
- Rstudio link - A IDE (Integrated development environment) que você sempre vai utilizar. Todos os trabalhos, análises - e literalmente TUDO - vão ser no Rstudio, ok?
Essa é a cara do Rstudio:

- Editor: você pode criar scripts, documentos e outros, basicamente lá é onde você irá salvar os seus códigos em uma pasta escolhida no seu computador. Para fazer o seu código “rodar”, você pode selecionar o código ou linha e apertar “RUN” ou na última linha do código que você quer fazer rodar apertar o comando: CTRL+ENTER
- Console: Local que o seu código roda, tanto o que você fez no editor ou que insere diretamente no console.
- Output: em Plots ou Viewer você poderá ver o resultado visual do seus gráficos. Files são as pastas do seu computador.
- Global Enviroment: Todos os objetos que você criar ficarão aqui
Tipo de dados que você trabalhará no R
- integer: números inteiros
- numeric: números decimais
- complex: números complexos
- logical: FALSE, TRUE, NA
- factor: categórica ex: (“ótimo”, “bom”, “médio”, “ruim”)
- character: texto ex: (“eu amo bolo de chocolate”)
Exercício inicial: Olá Mundo!
No seu console do R digite oi <- "oi mundo!". Esse código indica que você está atribuindo valor <- ao objeto oi, que acabou de criar, no caso, atribuindo a variável character “oi mundo”. Se você quiser ver esse objeto é só digitar no console:oi
Principais atalhos no Rstudio que vão te ajudar!
CTRL+ENTERroda a linha selecionada do script.ALT+-: atribuir variável (<-) .ALT+SHIFT+K: janela com todos os atalhos disponíveis.
O maravilhoso mundo do R ✨
Vamos ver alguns exemplos desse novo mundo.
Antes de tudo, precisamos instalar alguns pacotes do R. Mas o que raios são pacotes? Os pacotes são grande parte de onde está a mágica do R, eles são definidos como:
> Packages are the fundamental units of reproducible R code.
Mas eu prefiro entendê-los como se fossem caixas de ferramentas, que dentro há ferramentas que vão me ajudar a implementar o meu projeto. Há uma infinidade de pacotes (libraries), criadas diariamente por pessoas de todo o mundo (vantagens do open-source), cada uma dessas caixas, possuindo ferramentas diferentes!
(literalmente, copie e cole os códigos abaixo e veja a mágica acontecer)
Instalar pacotes:
#Para instalar os pacotes é só tirar o # da frente, ele funciona como comentário
#install.packages("tidyverse")
#install.packages("geobr")
#install.packages("gapminder")
#install.packages("modelr")
#install.packages("tidyverse")
#install.packages("ggcorrplot")
#install.packages("hexbin")
#install.packages("sf")#carregar pacotes
library(tidyverse) # o pacote mãe, soberano, é uma coleção de pacotes para data science
# library(ggplot2) faz gráficos (pacote dentro do tidyverse)
# library(dplyr) manipulação de dados (pacote dentro do tidyverse)
library(geobr) # mapas br
library(sf) # mapas
library(modelr)
library(gapminder) # banco de dados
library(lubridate) # processamento de datas
library(hexbin) # gráficos hexagonais
library(ggcorrplot) # correlação de dadosEx 1: scatterplot (o famoso gráfico de dispersão)
No caso, você está analisando uma base de dados de carros, comparando o tamanho do motor displ e com a eficiência do combustível hwy. Basicamente você está informando que você quer que a base de dados mpg se torne um gráfico, acionando a função ggplot e indicando em aes que a variável x será a coluna displ que está dentro da base mpg e a variável y será a coluna hwy, que também está dentro da base mpg.
mpg %>% ggplot(aes(x = displ, y = hwy, color = class)) +
geom_point()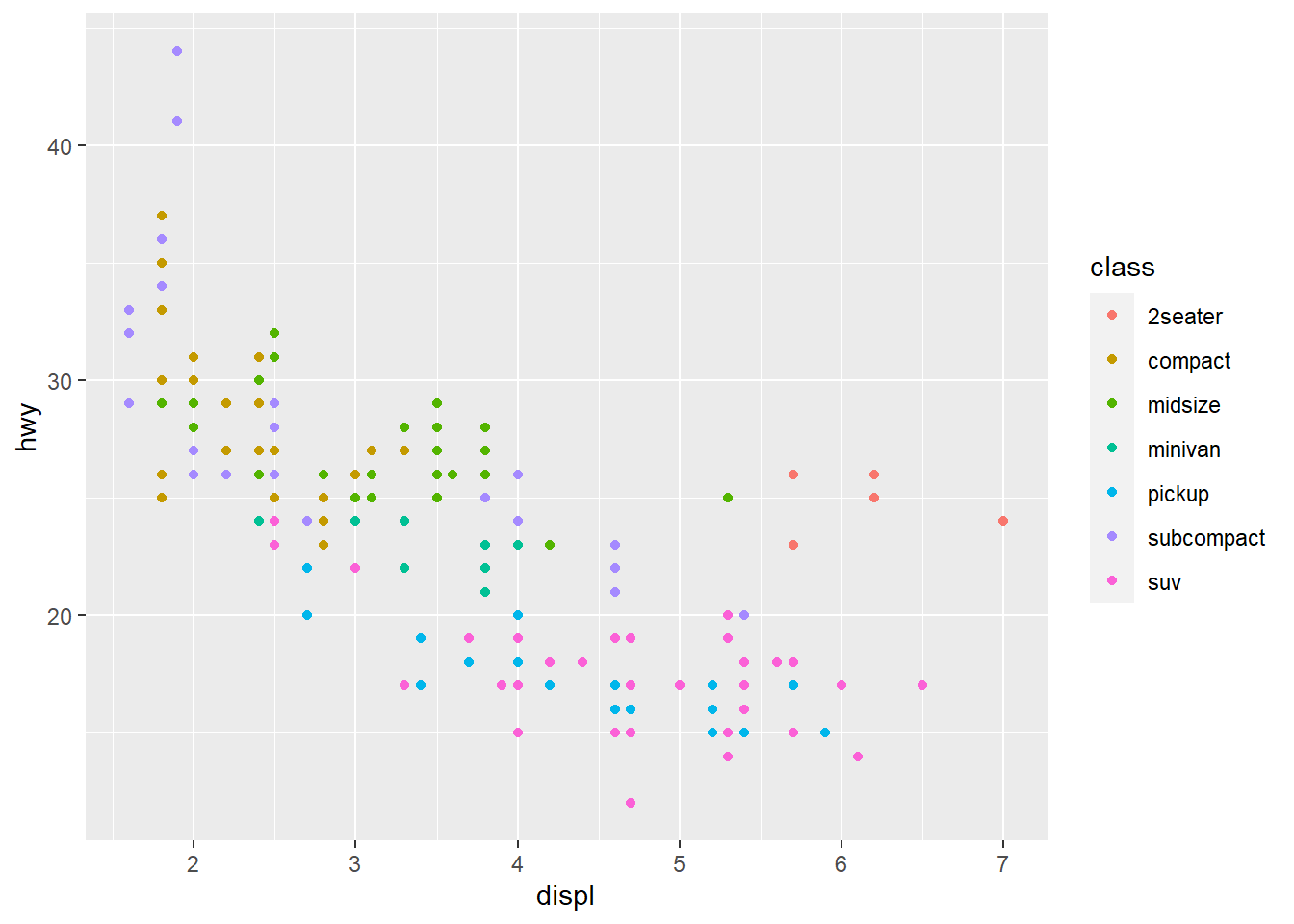
Antes de continuar é importante esclarecer o que é %>%, isso é algo que você vai usar muito e se chama “pipe”
O pipe “pega” o que está do lado esquerdo e roda no lado direito do código, facilita sua vida porque você não precisa mil objetos, já que há diversas etapas no processo.
Outro ponto importante para você entender antes de avançarmos é em relação a função ggplot. Basicamente quando você precisa indicar quais são os seus eixos do gráfico, dentro de aes e depois que tipo de gráfico que você que fazer. Atenção: a conexão entre o ggplot e o tipo de gráfico de você vai fazer é caracterizada com o sinal de +, NÃO o %>%
Ex 2: gráfico de barras
Aqui você está analisando a base de dados diamantes e fazendo um gráfico de barras do corte dos diamantes! Você não precisa de uma variável y aqui porque com o geom_bar o R vai identificar que cut é uma variável não númerica e vai fazer a contagem para você!
diamonds %>% ggplot(aes(cut)) +
geom_bar()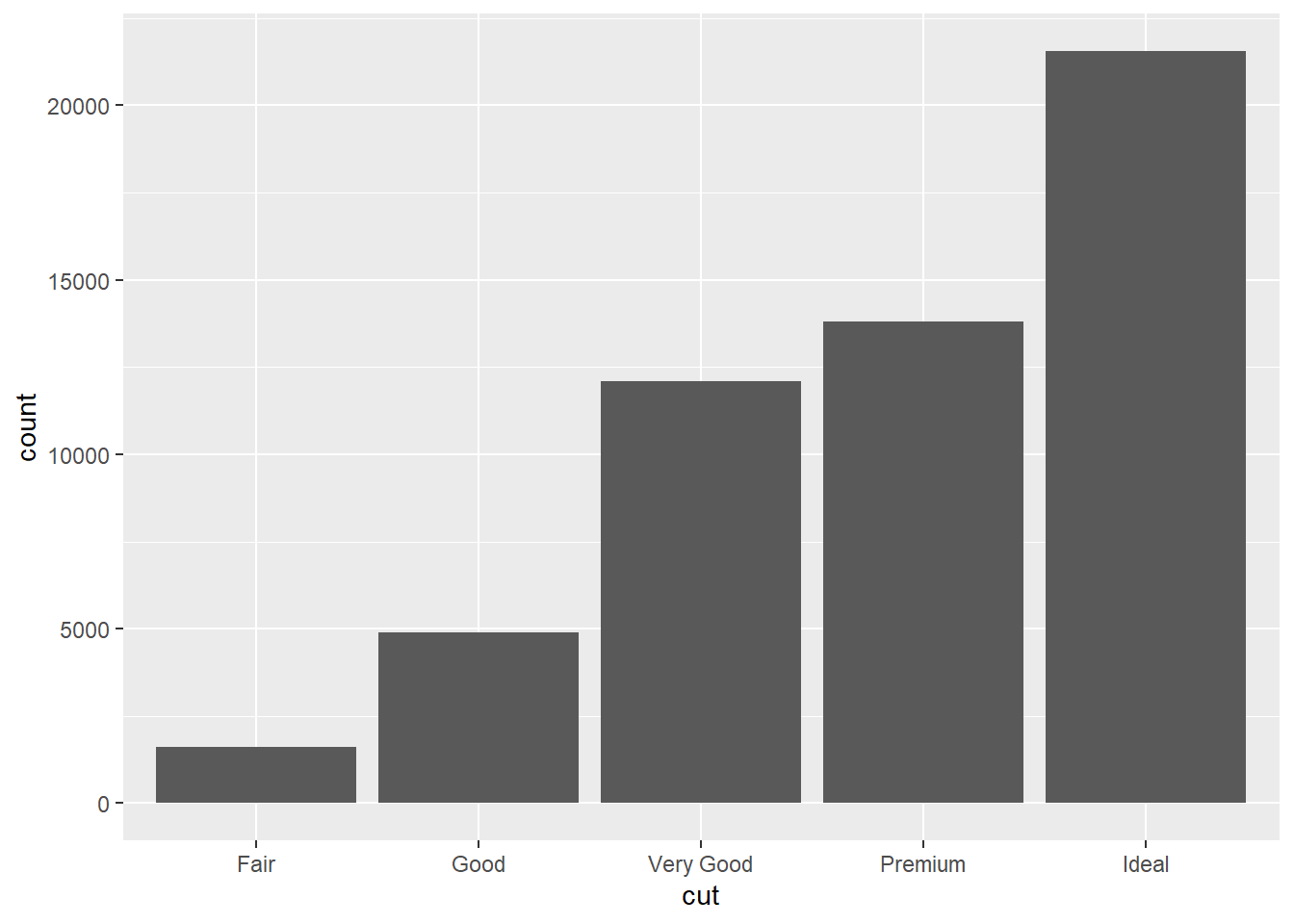
Ex 3: mapas
Sim, o R também faz mapas 🌎. Esse código acontece em 3 etapas:
1. Criar uma variável chamada “no_axis”. Seu objetivo é basicamente deixar o mapa mais limpo, sem a trama e os eixos que normalmente ficam atrás dos gráficos. Como faremos um mapa, queremos limpar todo esse “plano de fundo”.
no_axis <- theme(axis.title=element_blank(),
axis.text=element_blank(),
axis.ticks=element_blank())2. Organizar nossa base de dados. Vamos criar a variável “states”, que vai conter as informações dos estados brasileiros contidas no pacote “geobr”. Serão 27 observações no ano de 2014, uma para cada estado brasileiro.
states <- read_state(year=2014)## Using year 2014## Loading data for the whole country3. O Mapa! Agora que já temos nossa base de dados organizada, vamos dar o play. O geom_sf é o responsável por gerar o mapa e todos os argumentos dentro dele são as informações necessárias para que ele construa o que a gente quer:
- data → base de dados (no caso, é a “states”, que acabamos de criar)
- fill → cor do preenchimento dos estados
- color → cor do perímetro (linha) de cada estado
- size → espessura da linha (perímetro de cada estado)
- show.legend → está marcada como FALSE pois não queremos que ela apareça
- O “labs” são as labels (títulos, subtítulos, etc) que você vai dar para o seu mapa. Nesse caso queremos que ele se chame States. Por fim, estamos adicionando o plano de fundo “minimal” e a nossa variável “no_axis”, garantindo que o mapa fique o menos poluído possível.
ggplot() +
geom_sf(data = states, fill="#2D3E50", color="#FEBF57", size=.15, show.legend = FALSE) +
labs(subtitle="States", size=8) +
theme_minimal() +
no_axis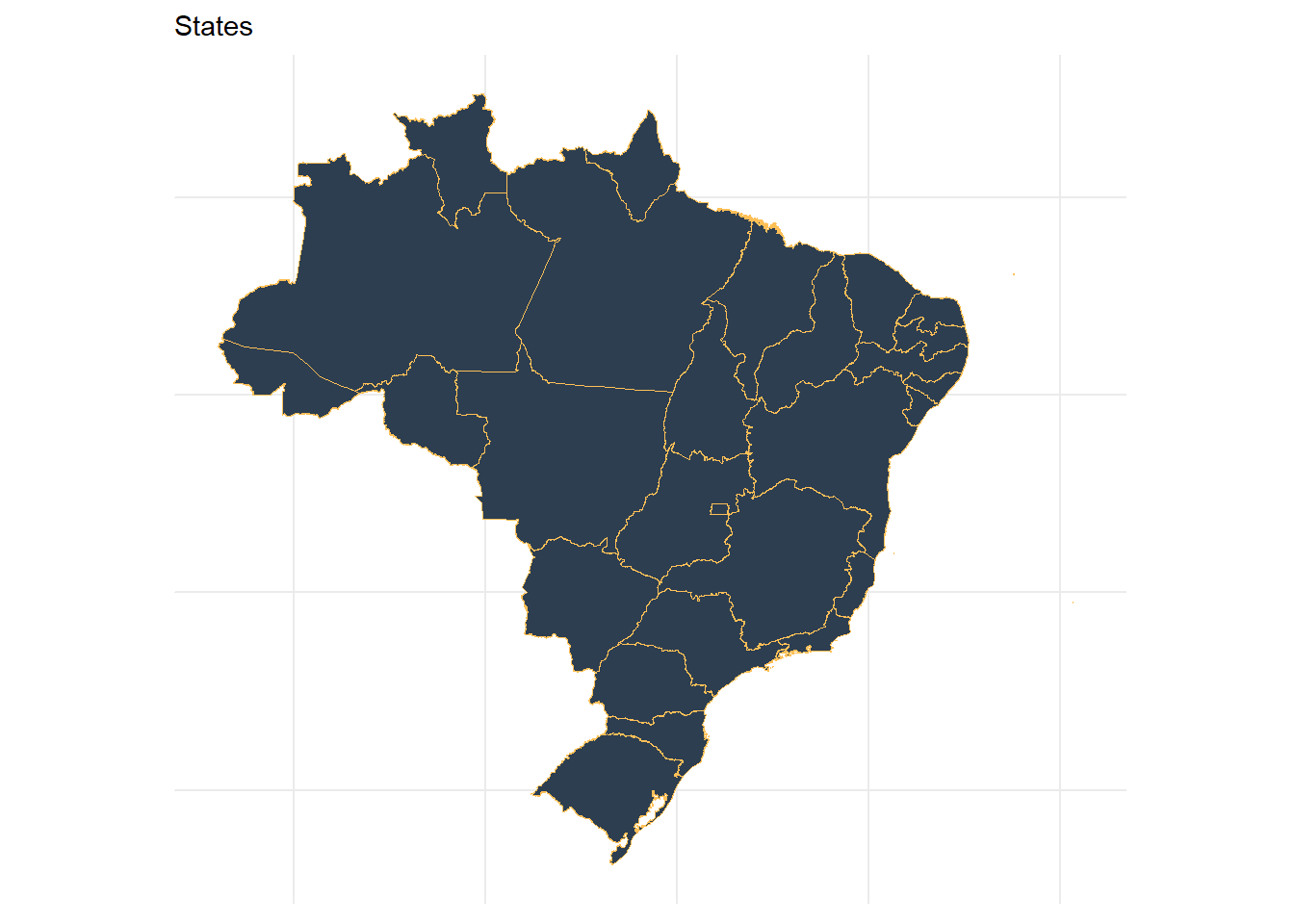
Ex 4: gráfico de correlação
Aqui estamos usando a base de dados Diamonds, uma base que já vem inclusa dentro do pacote ggplot. Queremos entender se existe correlação entre os dados numéricos,ou seja:
- x = comprimento (milímetro)
- y = largura (milímetro)
- z = profundidade (milímetro)
- price = preço
Medidas complexinhas, entendedores de diamantes entenderão, rs ~ não foca nessas informações, o foco é entender o gráfico.
- depth = percentual de profundidade total
- table = largura do topo do diamante relativa ao seu ponto mais largo
Para isso, estamos selecionando só as colunas com números select(5:10). O resultado será um gráfico de correlação:
- correl positiva entre 2 variáveis: cor laranja
- correl negativa entre 2 variáveis: cor azul
- sem correlação entre 2 variáveis: cor branca
diamonds %>% select(5:10) %>%
cor() %>%
ggcorrplot(hc.order = TRUE, type = "lower",
outline.col = "white",
ggtheme = ggplot2::theme_gray,
colors = c("#6D9EC1", "white", "#E46726"))
Ex 5: gráfico de hexágonos
Esse gráfico é uma solução para quando você tem muuuuitos dados e a visualização no gráfico de dispersão fica poluída e te dificulta tirar qualquer conclusão. Basicamente, para evitar que os dados se sobreponham esse gráfico divide a área em pequenos fragmentos, no caso hexágonos, dividindo os valores dentro desses hexágonos (bin), por isso possui a legenda ao lado indicando a contagem, quanto mais escuro maior a presença de dados dentro daquele hexágono. No caso estamos analisando a relação entre duas variáveis numéricas, preço e peso.
ggplot(diamonds, aes(carat, price)) +
geom_hex(bins = 50)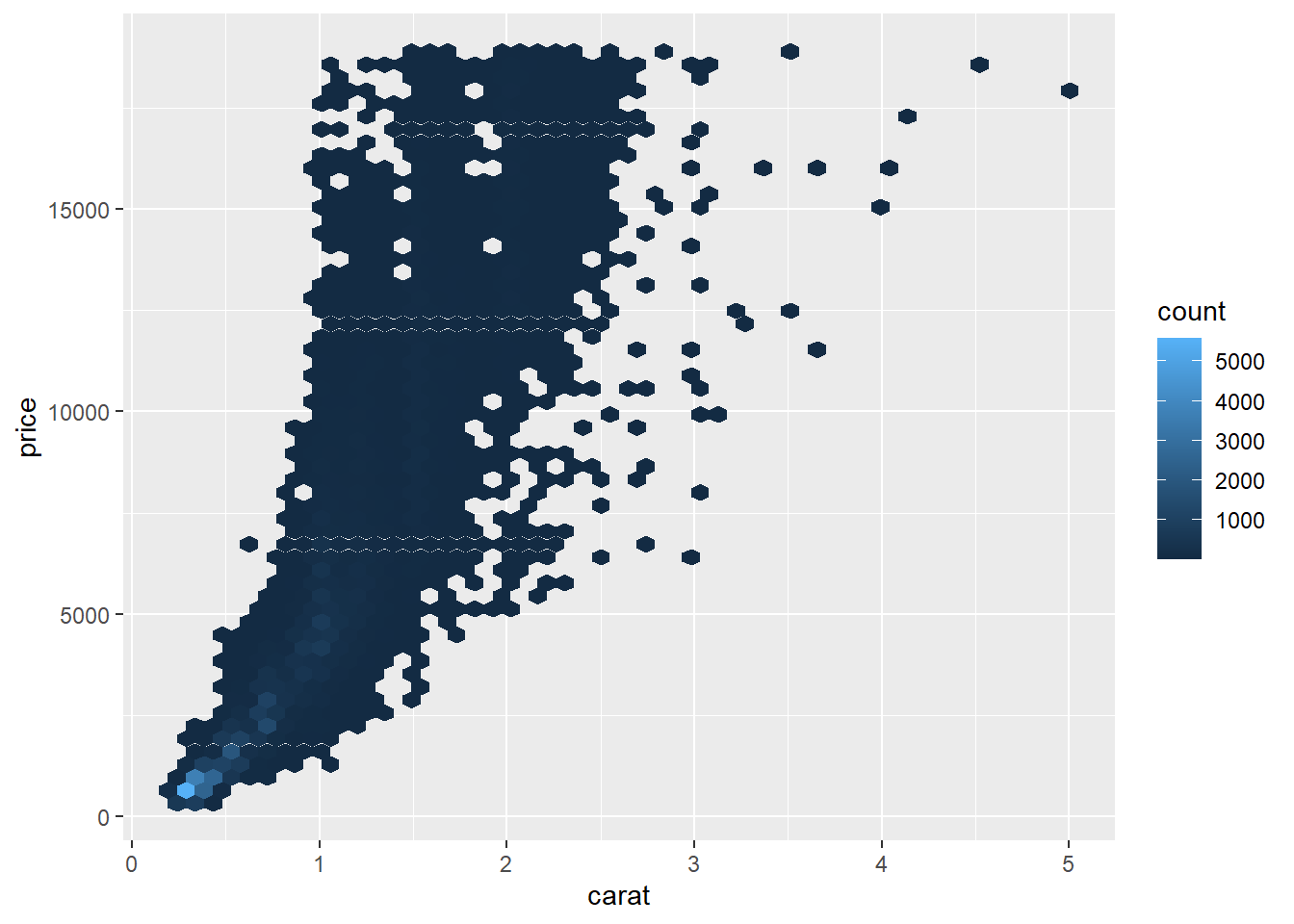
Primeiro projetinho no R: Visualizando dados
PARTE 2: EXPLORANDO ALGUMAS BASES DE DADOS
CASO MPG
Rode os códigos abaixo para entender o que é essa base de dados: mpg e ?mpg
PERGUNTA da análise:
Será que existe uma relação entre displ (tamanho do motor) e hwy (eficiência do combustível)?
Por esse gráfico que vamos rodar agora, parece que sim.
mpg %>% ggplot(mapping = aes(x = displ, y = hwy)) +
geom_point()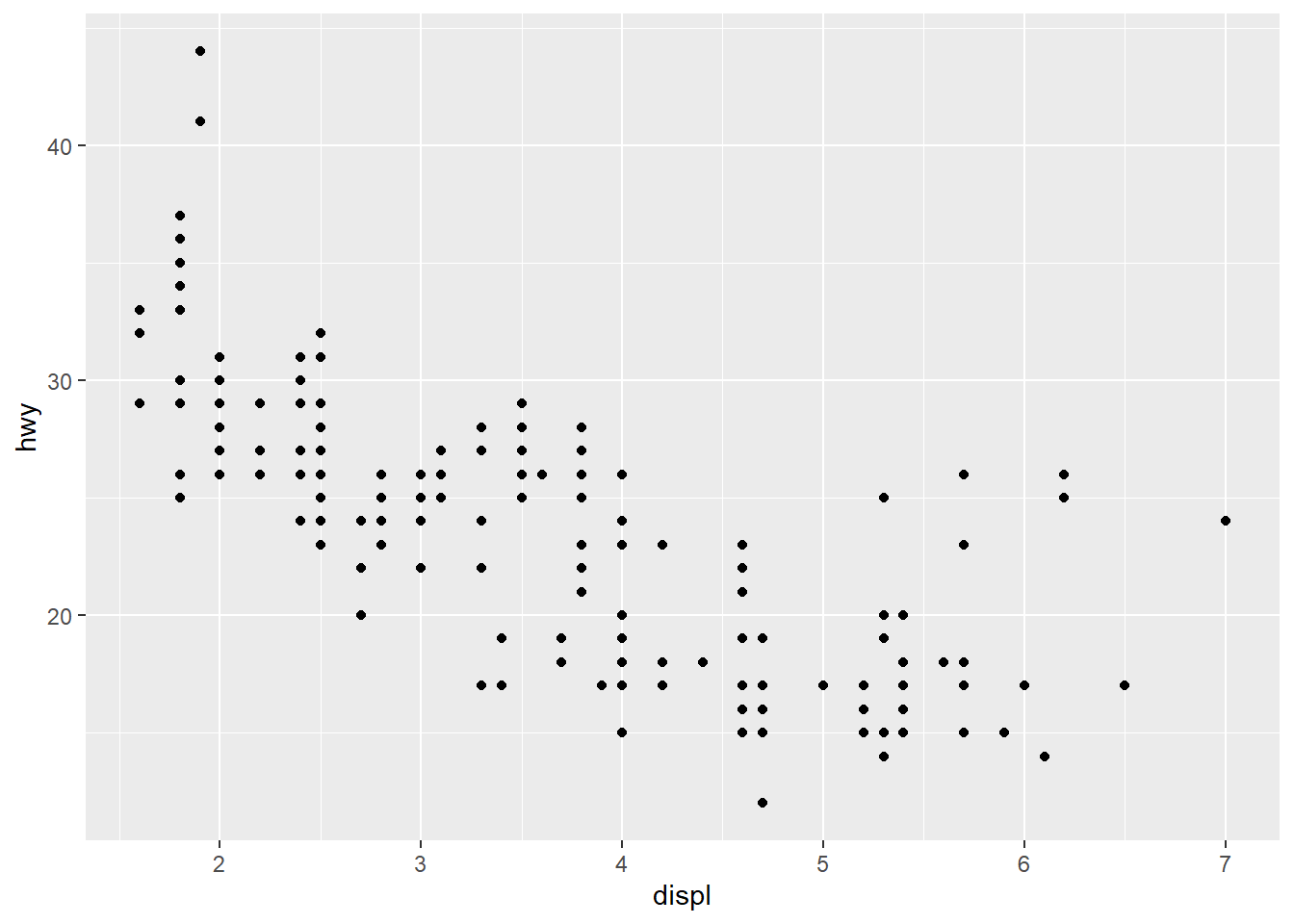
Podemos adicionar uma linha ao gráfico a fim de entendermos melhor o lugar em que os pontos estão posicionados
mpg %>% ggplot(mapping = aes(x = displ, y = hwy)) +
geom_point() +
geom_smooth(se = FALSE) # linha posicionada no lugar mais perto de todos os pontos## `geom_smooth()` using method = 'loess' and formula 'y ~ x'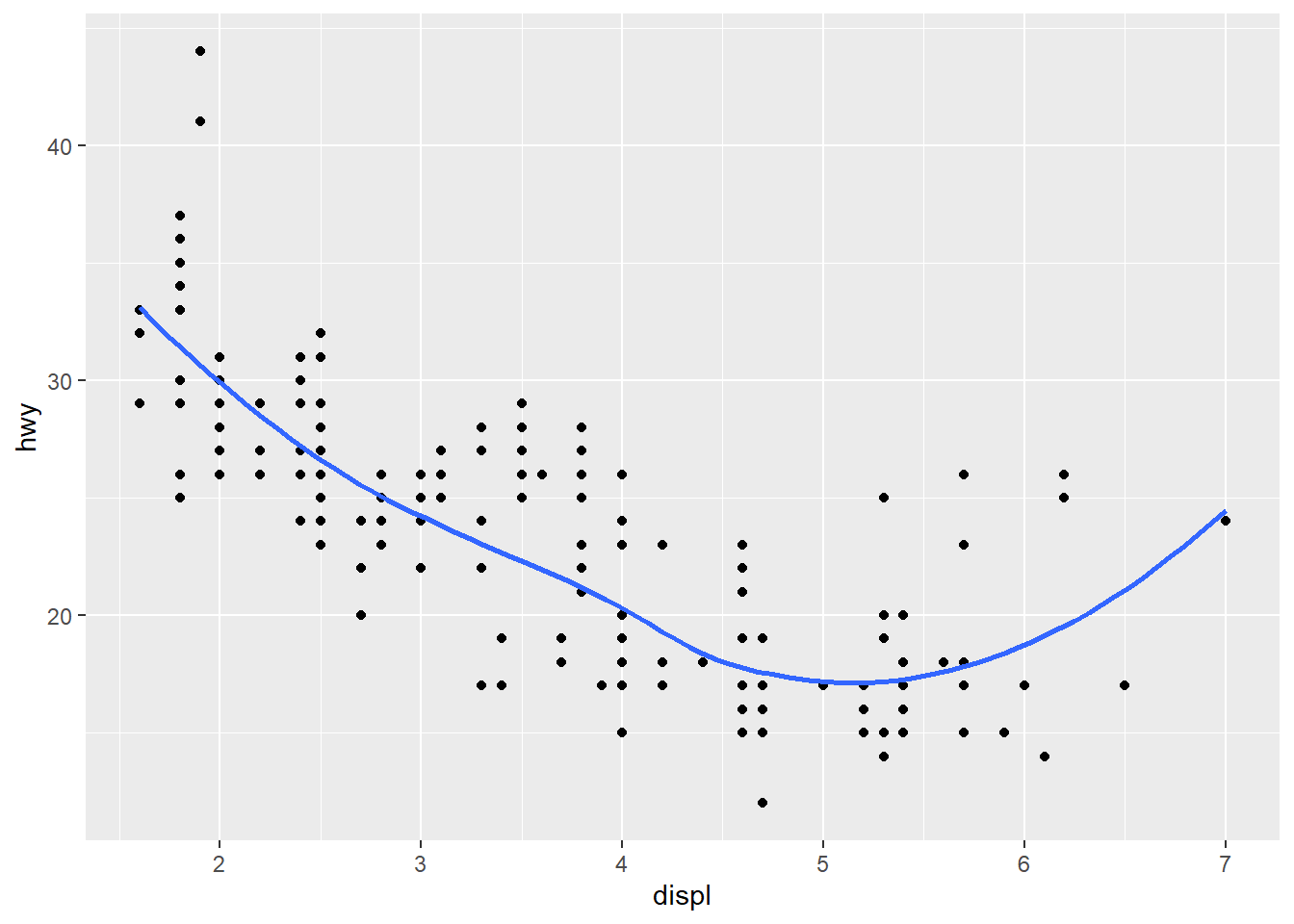
Podemos também adicionar mais uma variável: class.
Pra isso, nos utilizaremos de cores pra adicionar essa informação. Eu decidi usar cores, mas note que poderia ser qualquer outra coisa, como formas ou tamanho dos pontos. Para isso, troque o argumento “color” por “shape” ou “size”.
mpg %>% ggplot(mapping = aes(x = displ, y = hwy, color = class)) +
geom_point()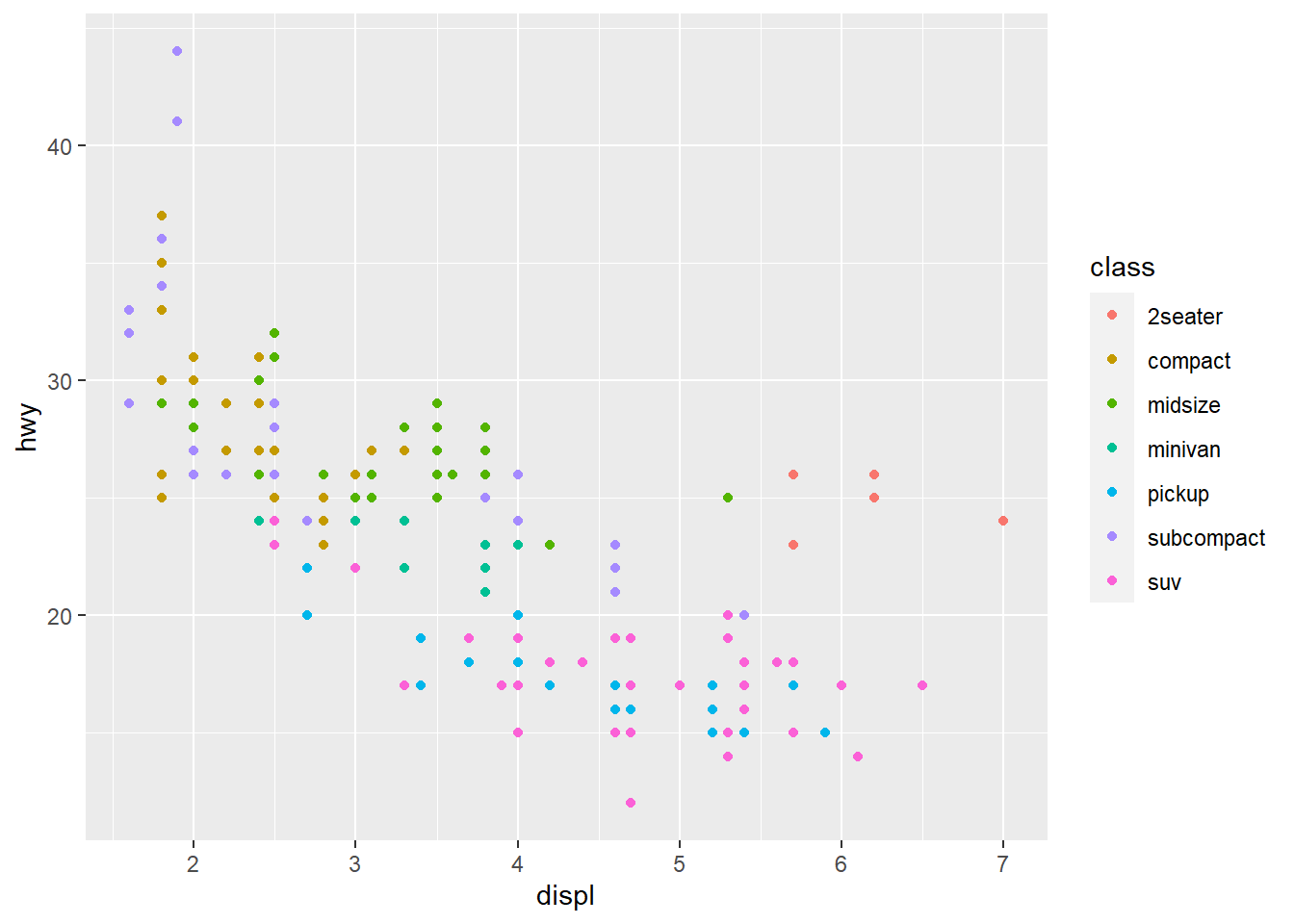
Agora vamos dividir nosso gráfico.
Rode o código abaixo e você verá que agora temos 7 gráficos! Cada um deles é específico de uma “class” de carros. Ou seja, ao invés de adicionarmos essa variável “class” através de cores, formatos, etc, estamos separando cada uma em um gráfico diferente.
mpg %>% ggplot(mapping = aes(x = displ, y = hwy)) +
geom_point() +
facet_wrap(facets = vars(class))
Quer mais conteúdo para se aprofundar? Aqui vão alguns conteúdos ótimos em português:
- R para cientistas sociais
- Github R ladies SP com diversos workshops
- Github R ladies Goiânia
- Youtube Rladies BH com intro ao R
- Blog Rladies BH
Para quem se aventura no inglês, segue o livro que eu leio vira e mexe volto pra ele em momentos de dúvidas, uma fonte de aprendizado ótima: R for Data Science
Outro que tem sido meu guia principal em visualização de dados é o Data to viz
Fique ligado nos eventos das R-ladies! Há sempre tutoriais e workshops super legais e gratuitos para todos! Há diversos R-ladies no mundo, aqui vão algumas dicas de perfis que eu sigo no instagram e github, recomendo!
- @rladiesp
- @rladiesthe
- @rladiesbh
R-ladies é uma iniciativa global que promove diversidade na comunidade R, realizando diversos compartilhamento de conteúdo, workshops, mentorias, eventos e conexões! Quem fundou essa comunidade GLOBAL foi a Gabriela Queiroz, brasileira e cientista de dados, lá em 2012, que acabou tendo muito sucesso e expandido para várias regiões do mundo
Isabella Pileggi
Bacharel em Administração Pública
Formada em Administração Pública pela FGV-SP e estudante de Engenharia de Software na Escola 42.
Mônica Rocabado
Data Analyst/Pesquisadora
Meus interesses de pesquisa incluem empregabilidade, desigualdade (com recorte em raça e gênero), análise de redes sociais, governo e políticas públicas.